네이버 뉴스, 구글 뉴스, 클리앙 게시판 등 특정 뉴스판이나 커뮤니티의 글을 자동으로 읽어서 메일로 보내거나, 메신저로 보내주는 것을 생각하는 개발자에게 우선 게시글을 읽는 것에 대해 설명하고자 한다.
사실 게시글(배열)을 읽은 후, 앞에서 배운 파일(csv, 엑셀등)로 생성하여 메일로 보내거나, 나중에 정리할 메신저(챗봇) 등으로 알림을 받을 수있다. 게시글을 읽는 방법은 보통 selenium이나 beautifulsoup 등을 활용하는데 이책은 selenium을 이용한다. 충분히 이용방법은 쉽다. 다만, 게시글을 분석하는 과정에서 요소(항목, 뉴스단위, 게시글 단위)를 어떻게 정의할지를 고민하고 익숙해 지는게 중요하다. 관련 방법에 대해서는 별도로 다시 정리하려고 한다.
#준비사항 #
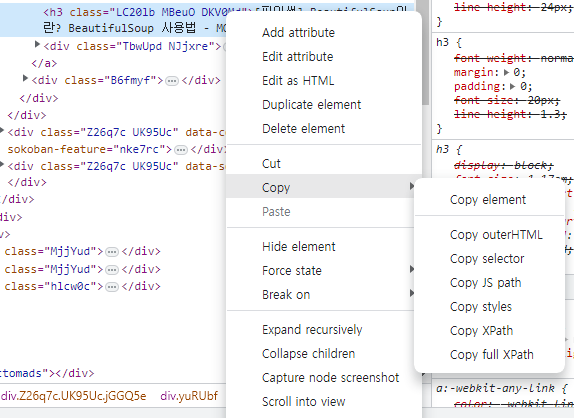
1. "크롬브라우저(대부분 브라우저 지원) 에서 F12 를 누르면 개발자 도구가 나온다. 그상태에서 크롤링할 게시글의 게시물을 오른쪽 클릭하여 '검사'를 클릭하면, 자동으로 해당 elemenet를 표시해준다." 이정도의 개발자 도구 이용 지식.

2. 해당 element를 오른쪽 클릭하면, 'copy' 메뉴가 있고, 세부적으로 element, styles, Xpath, full XPath가 있는데, 우리는 selenium을 통해 위의 값을 이용해서 해당 elements(복수) 들을 지사하여 가져와 값(url, text, value 등)을 가져올 수 있다. 여기서는 가볍게 html 기본 문법과 Xpath(div/a/li 같은 값)에 대한 막연한 지식(값을 보면 이런거구나 정도 이해할 수준)
3. selenium 설치 (cmd 창에서 pip install selenium 으로 수행 필요시 특정 다운 버전 설치(pip install selenium ==3.1.9 등)
4. 크롬 드라이버 설치(https://chromedriver.chromium.org/downloads) 하고, 크롬브라우저에서 'chrome://settings/help' 로 접속하면 자동 업데이트도 됨.
#개념 설명 #
1. 브라우저에 옵션값을 설정한후, webdriver로 특정 게시물 주소를 driver.get(url) 접속한다.
2. 검색란에 검색어를 send_keys입력한 후, Enter를 친다. send_keys(Keys.RETURN)
2. 위 2번이 싫다면, 1번 수행시 검색어로 검색한 페이지로 접속한다.
3. 게시글(element)를 분석해서 항목을 배열로 읽는다.(selector, xpath 등을 이용)
4. for을 이용하여 게시글마다 date, title, content 등을 읽는다. (필요시 엑셀로 저장)
5. webdriver를 quit().
* 페이지 이동간에 시간이 소요될 수 있어서 sleep(3) 1~3초 쉬는 시간이 필요한다.
from selenium import webdriver # 웹드라이버 호출 START
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager # 웹드라이버 호출 END
from selenium.webdriver.common.keys import Keys # 특수키(ESC, ENTER 등) 이용
import time # 시간
import datetime as d
from openpyxl import Workbook # 엑셀
xlsx = Workbook()
sheet = xlsx.active
sheet.append(['Title', 'Link', 'Published date'])
try:
options = Options()
options.add_experimental_option("detach", True)
options.add_experimental_option("excludeSwitches", ["enable-logging"])
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
keyword = 'python' # 검색어
driver.get('https://search.naver.com/search.naver?sm=tab_hty.top&where=view&oquery=&tqi=h%2ByOzwp0YihssO60XsCssssssxN-078282&mode=normal')
elem = driver.find_element(By.ID, 'nx_query')
elem.send_keys(keyword) # 검색어입력
elem.send_keys(Keys.RETURN)
first = driver.find_element(By.XPATH, "/html/body/div[3]/div[2]/div/div[1]/section/div/div[2]/panel-list/div[1]/more-contents/div/ul")
divs = first.find_elements(By.CLASS_NAME, 'bx._svp_item .total_area')
for div in divs[:10] :
title = div.find_elements(By.TAG_NAME, 'a')[5].text
pub_date = div.find_element(By.CLASS_NAME, 'sub_time.sub_txt').text
naver_link = div.find_elements(By.TAG_NAME, 'a')[5].get_attribute('href')
if not pub_date :
print('NULL')
continue
sheet.append([title, naver_link, pub_date])
except Exception as e :
print(e)
finally :
driver.quit()
nowDate = d.datetime.now()
file_name = nowDate.strftime("%Y-%m-%d") + '.xlsx' # '2023-03-05.xlsx' 형식으로 파일 생성.
xlsx.save(file_name)위의 소스를 실행하다보면, 'list index out of range' 오류가 발생한다. 위의 소스에서 for div in divs[:10] : 이렇게 divs 10개까지만 읽는 이유는 요즘 포탈사이트 중 초기에 10개를 보여주고 스크롤을 내려야 10를 더 보여주고 있어서 오류가 발생하는데, 오류를 없애려면, 10개를 읽은 후에 스크롤을 내려면 된다. (driver.find_element_by_tag_name('body').send_keys(Keys.PAGE_DOWN) 또는 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
버전에따라 element를 찾는 함수 모양이 변경되었다. 오류 발생시 버전에 맞게 사용하면 되고, ID같이 유일한 값은 find_element로 검색해야 하지만, 복수개가 가능한 요소는> find_elements < 로 배열형태로 읽을 수 있다. 만약 css 클래스처럼 복수가 가능한 항목을 find_element로 읽으면 첫번째 항목이 반환된다.
| driver.find_element_by_id('ID명') | driver.find_element(By.ID, 'ID명') | 유일한 값으로 검색 |
| driver.find_elements_by_class_name('클래스명1.클래스명2') | driver.find_elements(By.CLASS_NAME, 'C명.C2명') | 복수, 단수 검색 가능 |
| driver.find_element_by_xpath('Xpath') | driver.find_element(By.XPATH, 'Xpath') | 상대, 절대 모두 검색 가능 |
책을 보면 사이트들의 구조가 변경되었을 수도 있기에 그대로 실행이 되지않을 수 있고, 인터넷에 있는 것은 버전에 따라 함수값을 추가로 변경해줘야 할 수도 있다. 무엇보다. 이것은 정답이 없다.! 조건에 맞게 가져오기만 하면 된다.
귀찮아서 모두 Xpath로 사용해도 무방하고, css selector를 사용해도 무방하다. 아래의 예제에는 백그라운 실행을 통해 이용중인 PC에서 돌아가게 설정했으며
(options.add_argument('headless'), options.add_argument('window-size=1920,1080')
timedelta를 이용해서 120일 이내 글 중에서, 검색키워드가 포함된 게시글만 읽어서 개인 메일로 보내도록 했다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
import time
from datetime import datetime, timedelta
from my_email import send_email
job_dir = 'C:\\workspace\\scheduler\\job'
try :
options = Options()
options.add_experimental_option("detach", True)
options.add_experimental_option("excludeSwitches", ["enable-logging"]) #불필요한 오류메시지 제거
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64")
options.add_argument('headless') # 백그라운드
options.add_argument('window-size=1920,1080') ## 자동화 실행시, PC의 화면 밖에서 실행되도록(백그라운드) 조치, 백그라운드 시 화면 최소화 방지를 위해 사이즈 고정
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
today = datetime.now()
diff = timedelta(days=120) # 최근 120일 이내 게시글 검색
base_date = today - diff
base_date = base_date.strftime('%Y.%m.%d.')
#keyword = open(job_dir + '\\keyword.txt', 'r').readlines() #키워드 파일로 저장할 경우
keywords = ['디지털','환경','연구']
matches =[]
driver.get('https://www.msit.go.kr/bbs/list.do?sCode=user&mPid=224&mId=129')
time.sleep(1)
elems= driver.find_elements(By.XPATH, "//*[@id='result']/div/div")
for elem in elems :
title_tag = elem.find_element(By.XPATH, ".//a/div[2]/p")
date_tag = elem.find_element(By.XPATH, ".//div[starts-with(@id,'td_REG_DT')]")
print(title_tag.text, date_tag.text, sep='|')
if date_tag.text > base_date :
for k in keywords :
if k.strip() in title_tag.text : # strip() 공백제거.
matches.append(f'{date_tag.text} : {title_tag.text}')
break
if matches :
contents = '최근 올라온 공고가 있습니다. \n\n'
contents += '\n'.join(matches)
send_email('recv@mail.com', '***게시글 확인', contents )
else :
print('최근 공고가 없습니다')
except Exception as e :
print(e)
finally :
driver.quit()'개발자 넋두리 > 파이썬(Python)' 카테고리의 다른 글
| (업무자동화) 별첨. 파이썬 문제 해결 사례 (0) | 2023.03.06 |
|---|---|
| (업무자동화) 별첨. 파이썬 웹로딩 기다리는 방법2가지 (0) | 2023.03.02 |
| (업무자동화) 파이썬 네이버 메일 보내기(3/5) (0) | 2023.02.27 |
| (업무자동화) 파이썬 파일, 엑셀 다루기(2/5) (0) | 2023.02.24 |
| 개발자에게 미리 알려주는 파이썬 개념(1/5) (1) | 2023.02.24 |





