성장하는 스타트업은 완벽 보다는 필요한 것부터 차근차근
통계전문가, 빅데이터 전문가의 역할은 무엇일까요? 비즈니스 전문가, IT기획자 또는 개발자가 데이터 항목간의 연관성, 의사결정을 위한 통계, 판매 실적 추이, 특이점 등을 찾아낼 수 있도록 DW 환경을 구축하는 것입니다. 그렇게 하기 위해서 실거래 DB부터, 디멘젼 테이블, ODS, 메타관리, 데이터품질관리 마지막으로 효율적인 협업 시스템을 구축해야 합니다.
스타트업으로 시작한 토스는 Simplicity21에서 나온 "오직 한사람, 사장님을 위해" 같은 다양한 통계를 활용한 서비스를 기획할 수 있는 큰 규모 DW를 구축할 수 있었습니다. 그들은 6개의 원칙을 갖고 성장할 수 있었습니다.
DW업무를 처음 접하시는 분들은 토스의 과정을 보시면서, 막연한 DW에 대해 감을 잡으시기 바랍니다.

DB Review
IT직원이 30명이 넘는 규모의 회사에서도 별도의 DBA를 두지 않고, 개발자가 임의로 테이블을 추가, 수정하면서 데이터의 중복, 비효율적인 Index생성/누락 이 빈번한 회사가 많습니다. 토스는 DBA가 컴플라이언스(개인정보, 암호화, 권한 관리 등)와 데이터 모델, 성능과 안정, 운영 효율성 관점에서 리뷰를 진행하고, 안전하고 효율적인 방법으로 DB 변경 작업을 수행합니다. 운영DB의 품질(중복 최소화, 적절한 Index, 용어 통일, Null값 관리, FK, comment 설 등)이 낮으면, DW의 품질 또한 높을 수 없습니다. 또한 용어 통일이 되지 않으면 커뮤니케이션 오류, 데이터 중복관리 등 불필요한 업무가 계속 발생합니다.
디멘젼 테이블
차원에 대한 테이블(일별, 월별, 코드별 등 집계 기준)은 자동화를 위한 선제 조건입니다. 주요 행위나 서비스에 대한 정의(d_act_type, d_svc), 각종 수수료 및 매출 계약정보 등을 분류 기준을 만들어 집계시 하드코딩하지 않고 디멘젼 테이블로 관리해야 일관성을 유지할 수 있습니다. 코드명별로 Min, Max값에 따라 코드값으로 값을 적절히 분류하면, ODS 테이블에 적재시 동일한 기준으로 Summary 테이블 생성 가능합니다.
| 영문코드명 | 한글코드명 | 코드 | 코드값 | Min값 | Max값 |
| CUST_TP_CD | 고객유형코드 | CU_GOLD | "골드"등급 고객 | 50,001 | 10,000,000 |
| CUST_TP_CD | 고객유형코드 | CU_BRONZ | "브론즈" 등급 고객 | 0 | 50,000 |
| USAGE_OF_ FREQUENCY |
이용빈도 | UOF_1000 | 1,000번 이용 | 0 | 1,000 |
토스는 구글스프레드시트로 Python으로 MySQL 같은 RDB 데이터를 동기화하는 프로그램을 만들어 사용.
* 중견기업 이상, 금융권에서는 DW를 구축하면서 ETL(Extract Transform Load) 프로그램을 통해 설정된 Mapping rule대로 적재하며, 네티짜의 경우 SQL문으로 메모리에서 DB to DB 데이터를 적재(매우 효율적임)
ODS 설계 및 운영
ODS(Operational Data Store)란 집계효율을 위 중간 가동단계의 데이터들의 저장소입니다. 운영시스템의 복잡한 형태를 단순화하거나 표준에 맞지 않는 부분을 전처리 과정(Null값 통일)을 통해 맞추기도 합니다. 또한, 필요에 따라 Summary 테이블로 구성할 수도 있습니다.

* AARRR : 데이터를 보는 하나의 방법론으로 이용자의 유입에서 매출로 연결되기까지 단계별로 분석하는 방법

이런 공통된 지표들을 윗 단계(Dimension 테이블)에서 정의하여 관리합니다. 그래야 모든 팀에서 공통으로 활용할 수 있습니다.

행위(공통된 지표)에 대해 정의하였기에 단순한 SQL으로도 다양한 행동들에 대한 상관관계를 쉽게 파악할 수 있습니다.
이런 모든 일련의 과정을 Sql 스크립트를 작성해서 돌릴 수도 있지만, 토스는 AirFlow를 사용하고 있습니다. 이미 정보계를 구축한 회사에서는 이미 자체적으로 개별 스크립트를 모듈로 작성해서 Diagram을 만들어 운영 중일 것입니다.

효율적인 협업을 위한 도구
Jenkins를 이용하면 사용방법이 쉬워 비개발자들도 쉽게 배치를 등록할 수 있었으나, 관리가 어려워 체계적인 관리를 할 수 있는 체계를 마련할 필요가 있습니다. 간단하거나 지엽적인 것은 비개발자들에게 허용할 수 있지만, 영향도가 높은 경우에는 IT부와 협의를 통한 관리가 필요합니다.
통계 프로그램(SQL) 역시 형상관리가 필요하며, 문제 발생시 담당자를 확인할 수 있게 명시하고, 작업이력도 관리할 수 있어야 합니다. 또한 작업 상세 설명을 검색할 수 있어야 중복 작업을 없앨 수 있습니다.

메타정보 관리
테이블명, 컬럼마다 comment를 등록해야 합니다. (우선 용어 정리를 먼저 해야겠군요.) 항목에 대한 의존성을 체크할 수 있는 기능이 있으면 좋겠지만, 필드에서는 의존성 검색하는 경우가 매우 드문 것 대비, DB 항목별 의존성(이용 메뉴)를 찾고 관리하는 비용이 매우 높아 주요 필드 위주만 관리하는 것도 방법입니다.
과거에는 ERD를 그리고 PK와 FK를 연결하는 매우 고가의 솔루션들을 많이 도입했었지만, 실제 변경이 적어 관리에 소홀하다보니, 최신화가 되지 않는 현장들이 많습니다. 또한, FK를 설계할지라도 운영상 오류 방지를 위해 FK를 설정하지 않아, ERD의 그림과 DB의 스키마의 설정이 달랐습니다. 따라, ERD를 통하지 않아 직접 DB를 정의하다보니 차츰 ERD를 관리하지 않아 요즘에는 거의 유명무실해졌습니다.
오히려 엑셀에 표로 테이블 구조를 관리하는 것이 적합할 수 있습니다.
데이터 품질
DW환경이 어느정도 안정화되면, DQ(데이터 품질, Data Quality)를 고려해야 합니다. 데이터 완결성, 유일성, 유효성 등은 메타 데이터를 가지고 검증할 수 있으며, 시의적절성, 정확성, 일관성 등은 검증 로직을 활용하여 체크해야 합니다. 그외 데이터 분포, 이상거래 탐지 등이 있습니다.
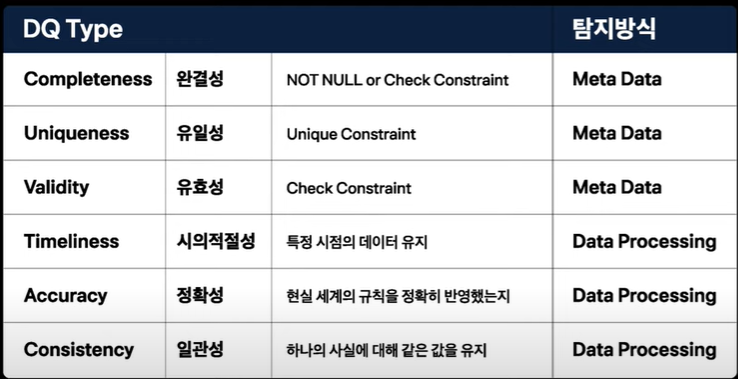
실시간 검증이 필요한 영역이 있고, ETL, DW 처럼 일, 주, 월 배치로 작업을 해야 하는 것도 있습니다. 최근에는 LOG, 변동분 기록을 새벽에 전날 기록을 옮기지 않고(일배치), 실시간으로 DW에 기록할 수 있도록 구성하는 회사도 있습니다. 이것은 이동시간(거래량에 따라 1~2시간 소요)를 최소화하고, 실시간으로 검증 로직을 활용하기 위해서입니다.

요약
• Risk의 크기를 고려하여 통제는 꼭 필요한 곳에만 적용, 기본적으로는 빠른 탐지와 대응 중심.
• 전사차원의 효율성을 고려하여 자동화, 체계화 진행 시기 결정
• 관리시스템 개발시 처음부터 완벽한 시스템을 만들려고 하지 않는다.
'반갑습니다. 신입님 > 토스컨퍼런스' 카테고리의 다른 글
| (SLASH 21) - Micro-frontend React, 점진적으로 도입하기 (0) | 2023.06.28 |
|---|---|
| (SLASH 21) DB구축시 고려사항, 가용성 - MYSQL HA & DR Topology (0) | 2023.06.28 |
| (Simplicity21) 어느 날 토스가 말을 걸기 시작했다 (0) | 2023.06.16 |
| (Simplicity21) 응답자에 마다 다른 답 - 그냥 사용자한테 물어보면 안돼나요? (0) | 2023.06.16 |
| (Simplicity21) 2년만에 변화된 금융IT - 불편한 경험 완전히 밀어버리기 (0) | 2023.06.15 |



