최근 형상관리에는 단순한 소스 버전 관리외에도 시큐어코딩 점검, 취약점 분석툴 등을 적절히 조합하여 운영하는 것이 대세이다.
1) 과거 소스관리를 "대장(종이문서)"로 관리하던 시절이 있었다. 그것을 전산화할 경우 별도로 대장관리를 하지 않아도 되어 소스 관리 프로그램이 주목받기 시작했으며, 2) 서버에서 소스관리하지 않고, 로컬에서 개인PC에서 개발하고, 최종 Object 파일만 운영에 배포하여 관리하다 보니 직무 변경(인사 이동)으로 소스를 잘 넘겨주는 것도 중요해졌다. 3) 대규모 시스템은 운영하다보면, 과거의 누군가의 코딩이 큰 부정적인 영향을 미칠 때, 책임자를 찾을 필요가 했다. 4) 대규모 시스템은 이중화 삼중화를 넘어 20대가 넘는 서버를 운용하다보니, 일괄 배포 시스템이 필요했다.
5) 물론, 소스를 임의로 수정하여 부정거래를 추적하기 위해 필요하기도 하지만 그것이 주요 도입취지는 아닐 것이다.
어쨌뜬, 임의 수정이 아니라 이슈 등록(업무 보고) 부터 개발 ~ , 취약점점검, 시큐어코딩 점검, 이행(승인절차 포함) 까지는 일련의 IT프로세스이다.
하지만 우리는 형상관리를 도입하면 업무 효율이 40%이하 저하되는 것을 염려해야 한다. 직접 소스를 ftp로 옮기는 것이 아니라, 형상을 타고 매번 시큐어코딩 점검을 하다보면 느리다... 정말 느리다...
하지만 필요하다. 그래서 현실에 맞는 절차를 도입하기 위해 고민하고 노력해야 한다. 특히 개발자의 의견을 최대한 듣고 존중해 줘야 한다. 만약 도입 이후, 기존대로 직접 소스를 배포한다면 결국 개인PC의 소스가 최종본이기에 형상시스템은 무용지물이될 것이다.
Shrink를 이용하기 전에, 검토해야 할것과 Shrink의 기능이 왜 생겨났는지를 알아야 한다.
우선, 여러분이 Delete 를 해서 Table에 수천만건이 있다가 1건으로 줄이더라도 실제 데이터를 검색하기 위해서는 이미 할당된 공간을 full scan하거나, High Warter Mark 까지 체크하는 것을 이해해야 한다.
그리고, Archive log에 변경이력이 쌓이는 걸 알아야 한다. Shrink는 데이터의 저장된 구조를 변경하는 것이다. (블록에 적재된 데이터의 량이 들쑥날쑥하고, row-chaining 등이 많다면, 동일한 데이터라도 table을 읽을 때 시간이 많이 걸린다).
그래서 triger로 인한 추가적인 DB변경은 발생하지 않지만, 실제 row를 delete/insert 작업을 통해 재정렬하는 것이기에 Archive log 파일이 대량으로 생성될 수 있다. 그래서 데이터가 많은 테이블을 Shrink할 경우에는 Archive log 의 디렉토리를 확인하여 백업이 된 log 파일은 삭제할 것을 권고한다.
제일 좋은 것은, 운영 중, 불필요한 데이터를 이관하거나 삭제하는 것이다. (개인정보보호법에 따라, 불필요한 정보는 즉시(5일이내) 삭제해야 하며, Log 테이블은 partition되어 있고, 매일 증가분에 대해 이관하였다면, drop partition을 통해 정리하는 것이 좋다.)
Shrink의 자세한 이론과 테스트는 아래의 내용을 참고하기 바란다.
어떤 세그먼트를 위해 공간이 크게 할당된 경우 High Water Mark 이후의 공간은 사용되지 않은 채로 남아 있게 될 수 있다. 또한 High Water Mark 이전의 영역에도 누적된 delete 연산의 결과로 빈 공간이 존재할 수 있다. 이 경우 다음과 같은 문제점이 있음을 알 수 있다:
데이터가 보다 많은 블록들에 걸쳐 흩어져 있으므로 스캔시 보다 많은 I/O가 필요하다.
내부 단편화로 인해 row-chaining/row migration이 일어날 가능성이 높다.
전체적인 공간 낭비가 발생한다.
Oracle9i에서 이러한 문제점들을 해결하는 방안은 해당 오브젝트를 이동하거나 재생성하는 것이었다. Oracle Database 10g에서는 이 문제를 위해 Segment Shrink 기능을 추가적으로 제공한다.
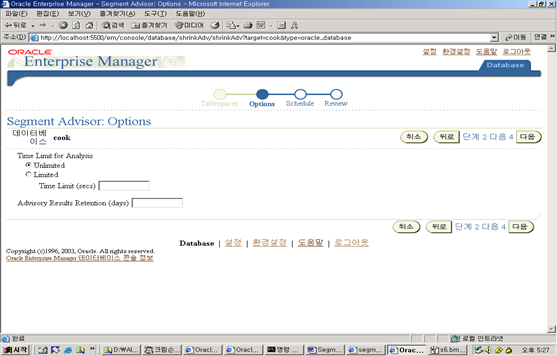
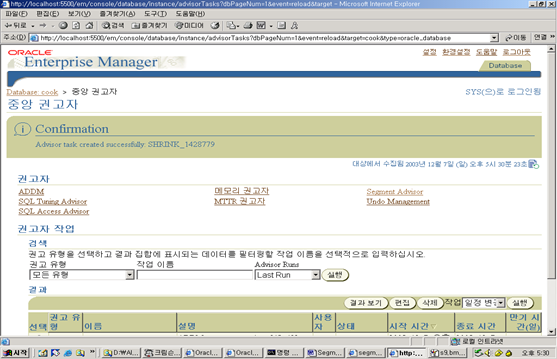
한편 Oracle Database 10g의 Advisory framework는 Segment의 공간 사용에 관하여 각종 통계 보고 및 Segment Shrink를 포함한 권고안 제시를 위해 Segment Advisor를 제공한다.
Segment Shrink의 원리
Segment Shrink는 다음의 두 단계에 걸쳐 이루어진다.
데이터의 compact
다만, 실제 데이터가 바뀌는 것은 아니기 때문에 DML 트리거가 정의되어 있다 하더라도 발생하지 않는다.
Segment Shrink가 row-chaining을 완전히 제거하는 것을 보장하는 것은 아니다.
보통의 DML과 같은 방식으로 이루어지므로 인덱스 dependency는 자동으로 처리된다. 다만 IOT에 대한 2차 인덱스는 shrink 직후 재생성하는 것을 권장한다.
이 단계는 HWM 아래 영역에 있는 hole들을 채우는 작업이다. 이는 내부적으로 INSERT/DELETE 연산에 의해 이루어진다: HWM에 가까이 있는 행을 안쪽의 빈 공간을 찾아 INSERT하고, 그것이 끝나면 해당 행을 DELETE함으로써 행을 옮기는 것이다.
HWM의 push down
1번 단계에 의해 데이터는 HWM에서 먼 쪽에 촘촘히 채워져 있을 것이고, 반대로 HWM에서 가까운 쪽의 공간은 비어 있는 상태가 된다. 이제 HWM를 내리고, 새롭게 설정된 HWM 이후의 모든 공간을 해당 테이블스페이스에 반납함으로써 segment shrink가 완료된다.
Segment Shrink는 online이자 in-place 연산이다. 1번 단계에서는 통상의 row-level lock이 필요할 뿐, 다른 세션의 DML을 불허하는 것은 아니기 때문에 오브젝트의 가용성은 제한되지 않는다. 또한 2번 단계에서 HWM를 내리는 데 필요한 exclusive 테이블 lock은 매우 짧은 시간 동안만 필요하다. 한편 Segment Shrink가 Oracle9i의 online redefinition과 다른 점은 별도의 임시 공간이 없이 바로 그 오브젝트에 대해서 (in-place) 수행될 수 있다는 점이다.
Segment Shrink의 조건
오직 Automatic Segment Space Management(ASSM)를 사용하는 테이블스페이스 내의 세그먼트만이 shrink될 수 있다. 데이터의 compaction 정보는 세그먼트 헤더의 bitmap block을 이용하기 때문이다. 다만 다음의 세그먼트들은 ASSM 테이블스페이스 내에 있더라도 shrink될 수 없는 제한이 있다:
임시 세그먼트 및 Undo 세그먼트
클러스터 내의 테이블
LONG 컬럼을 가진 테이블
ROWID 기반의 materialized view가 정의된 테이블
LOB 인덱스
IOT mapping 테이블
IOT overflow 세그먼트
공유된 LOB 세그먼트
2. 데이터 compaction 단계에서 rowid가 변경되므로 해당세그먼트에 대해 미리 ROW MOVEMENT가 enable되어 있어야 한다.
SHRINK SPACE 명령
테이블 세그먼트에 대한 segment shrink 명령은 다음과 같다:
ALTER table table_name SHRINK SPACE [COMPACT] [CASCADE];
물론 테이블 뿐만 아니라 segment shrink를 지원하는 모든 오브젝트들에 대해 위와 같은 명령을 사용할 수 있다.
COMPACT 옵션이 지정된 경우 segment shrink는 1단계인 데이터 compaction까지만 수행되게 된다.
CASCADE 옵션이 지정된 경우 segment shrink는 dependent한 오브젝트들에 대해서도 자동으로 수행되게 된다. 예를 들면 테이블을 shrink하면서, 그 테이블에 대해 정의된 인덱스들 또한 자동으로 동시에 shrink할 수 있다.
Segment Advisor
Segment Advisor는 Segment Shrink를 포함한 Segment 관리를 위해 EM에서 제공하는 GUI이다. 이는 EM의 테이블스페이스 페이지, 스키마 오브젝트 페이지, 그리고 Advisor Central 페이지 중 하나로부터 access할 수 있다.
Segment Advisor의 기능은 다음과 같으며 필요한 자료들은 AWR로부터 제공받는다.
Segment Shrink
Segment Advisor는 어떤 오브젝트가 shrink 연산을 위한 좋은 후보인지를 권고한다. 이러한 결정은 그 세그먼트에 할당되었으나 사용되지 않는 공간의 크기, 세그먼트의 공간 사용 경향 등에 근거한다.
Growth Trend Report
세그먼트의 공간 사용 경향을 보고함으로써 DBA의 용량 계획을 돕는다. 이는 나아가 Proactive Tablespace Monitoring 기능과 연동된다.
New Segment Resource Estimation
EM의 새로운 세그먼트 생성 페이지에는 "크기 예측" 버튼이 있어 이를 이용하면 필요한 디스크 크기를 예측할 수 있다. 이는 세그먼트의 구조, 예상되는 행의 수 등에 근거한다.
테스트
테스트 1: Segment Shrink
1. 테스트를 위해 테이블을 하나 생성하고 데이터를 입력해둔다.
SQL> conn scott/tiger
연결되었습니다.
SQL> create table employees as select * from hr.employees;
테이블이 생성되었습니다.
SQL> insert into employees select * from employees;
107 개의 행이 만들어졌습니다.
SQL> /
. . .
SQL> /
27392 개의 행이 만들어졌습니다.
SQL> commit;
커밋이 완료되었습니다.
2. 이제 employees 테이블이 얼마만큼의 공간을 차지하고 있는지를 확인해보자.
SQL> select count(distinct dbms_rowid.rowid_block_number(rowid)) blocks from employees;
BLOCKS
-
556
SQL> select blocks, extents from user_segments where segment_name = ‘EMPLOYEES’;
BLOCKS EXTENTS
- -
640 20
첫번째 조회에서 얻는 blocks는 실제로 사용하고 있는 block의 개수를 나타낸다. 반면에 두번째 조회에서 얻은 blocks는 할당된 block의 개수, 즉 HWM를 나타낸다.
온라인 서비스는 멀티프로세스로 인해, 개별 거래의 속도가 느릴지라도 사용자가 느낄 만큼 속도가 느린 경우는 없다. 물론 조회시 where 조건들이 index에 등록되어 있지 않다면, 처음에는 속도가 느린 것을 느끼지 못할지라도 ... 자료가 쌓이면 속도가 느린 것을 느낄 것이다.
그럼 실행 쿼리의 실행시간 기준으로 TOP 10을 조회하여, 해당 where 조건에 항목들에 대해 인덱스를 생성해주면 된다.
인덱스 생성시에 모든 조건을 인덱스로 만들어서는 안된다. 데이터 1건인데, 인덱스가 10개면 실제 11개의 처리가 발생하므로, 속도저하가 발생하고 인덱스 실행 계획이 원하지 예상하지 못하는 방식으로 나와 문제가 될 수 있다.
인덱스는 무조건 5개 이하이다.
왠만하여 공통 인덱스는 모든 업무를 커버할 수 있도록 선정하고, 조회는 인덱스만 잘 설정되어 있다면 문제 없다.
만약, 배치업무를 수행하는데 느리다면, 다음 사항을 체크해 보자.
1. 조회시 인덱스를 이용하는지? 2. Array 작업을 수행하는지? 3. 중간중간 commit 을 수행할 수 있는지? 4. Counter 체크 5. 통계 정보 생성 6. 불필요한 과거 정보 삭제 7. 업무 프로세스 변경
1. 조회시 인덱스를 이용하는지? 또는 TABLE FULL SCAN 을 하는지? 만들었다고 생각하지 말고, 체크해보자. 그리고 인덱스는 순차적으로 차례대로 찾기 때문에 항목이 5개인 인덱스는 중간에 3번 항목이 없다면, 결국 1번과 2번 항목만 인덱스를 읽고 나머지는 range_scan을 하기 때문에 데이터량에 따라 항목 조절을 해야 한다.
2. Array 작업을 수행하는지? 대량의 작업은 기본적으로 다량 Fetch, 일괄 Insert(또는 Update)를 수행해야 속도가 빠르다. execute() * 10000 보다는 batch_Execute() * 5 가 몇십배 빠르다.
3. 중간중간 commit 을 수행할 수 있는지? 업무에 따라, 중간에 commit을 할수 있다면, 몇천건 또는 몇만건 단위로 commit을 수행한다면 재작업시 작업량을 줄일 수 있다. 검토 후 중간에 commit을 삽입하자.
4. Counter 체크 : 오라클의 sequence를 사용하지 않고, select max(seq) from tableA; 사용한다면, 당장 변경하라. * 혹시 개발자 중에서 SELECT TASEQ.nextval from BigTable where rownum =1; 로 개발했다면, 당장 변경하라. SELECT TASEQ.nextval from dual; 로 실제 수행속도는 테이블의 사이즈에따라 몇백배까지 차이 난다.
5. 통계 정보 생성 : 통계정보가 최신화 되지 않아 plan이 느릴 수 있으므로, Analyze 해보자.
6. 불필요한 과거 정보 삭제 :데이터의 사이즈에 따라, 성능이 저하될 수 도 있으므로 과거 정보 삭제나 parition 나누자.
7. 업무 프로세스 변경 : DB에서 index 타고, 기본적인 속도개선까지 했다면 프로세스 변경을 고려해 보자. 여기까지 한 후, 하드웨어 증설을 고려하자.
# 추가 설명. sql 구성요소들은 아래와 같은 순서로 실행 된다
1) FROM, WHERE 절을 처리 2) ROWNUM 조건 적용 3) SELECT COLUMN LIST 절을 적용 4) GROUP BY 절을 적용 5) HAVING 절을 적용 6) ORDER BY 절을 적용
그러므로, 4번의 예시처럼 의미없이 대량의 테이블에서 rownum <=1 을 하면, 대량의 자료를 fetch 한후 nextval을 가져오는 불필요한 작업이 발생하므로, dual을 적절히 사용하자.
추가 tip. SMS 제품에서는 Oracle에서 제공하 v$sql, DBA_HIST_SQLSTAT, DBA_HIST_SQLTEXT, DBA_HIST_SNAPSHOT 등의 테이블을 이용하여, TOP N Query(상위 N개의 쿼리)를 제공한다. 이것을 바탕으로 지연 서비스의 쿼리 실행계획 및 실행 단위의 소요시간까지 제공해준다. SMS제품이 제공해 주는 것외에 본인이 DBA 또는 고급 개발자로써, 서비스 품질을 위한다면, 아래의 내용을 참고하여 개선 대상을 찾아 고민해보자.
다만, 아래의 것은 여러분이 문제를 찾기 위한 Query일 뿐, 해결방법은 각양각색이므로 획일적으로 답할 순 없다.
반복하는 쿼리 중에서 총 수행시간이 긴 쿼리 찾기. (짧은 업무일지라도, 단일 프로세스로 처리되면 문제가 된다. 예를 들어, 30msec * 100만번이면, 300,00초= 6,000분 = 100시간이 된다.)
SELECT * FROM ( SELECT S.SQL_ID, ROUND(SUM(CPU_TIME_DELTA)/100000) CPUTIME, SUM(EXECUTIONS_DELTA) TOTAL_EXECUTED, DBMS_LOB.SUBSTR(SQL_TEXT,2000,1) SQLTEXT FROM DBA_HIST_SQLSTAT H, DBA_HIST_SQLTEXT S, DBA_HIST_SNAPSHOT T WHERE S.SQL_ID = H.SQL_ID AND H.SNAP_ID = T.SNAP_ID AND T.BEGIN_INTERVAL_TIME BETWEEN TO_DATE('20190513 09:00:00','YYYYMMDD HH24:MI:SS') AND TO_DATE('20190514 15:00:00','YYYYMMDD HH24:MI:SS') GROUP BY S.SQL_ID, DBMS_LOB.SUBSTR(SQL_TEXT,2000,1) ORDER BY 3 DESC ) WHERE rownum < 21 and CPUTIME > 1000 ;
ORACLE서버에서 수행시간이 긴 쿼리 찾기 쿼리 SELECT ROWNUM NO, PARSING_SCHEMA_NAME, to_char(ELAPSED_TIME/(1000000 * decode(executions,null,1,0,1,executions)),999999.9999 ) 평균실행시간, executions 실행횟수, SQL_TEXT 쿼리 , SQL_FULLTEXT FROM V$SQL WHERE LAST_ACTIVE_TIME > SYSDATE-(1/24*2) -- AND LAST_ACTIVE_TIME BETWEEN to_Date('20111226163000','YYYYMMDDHH24MISS') AND to_Date('20111226170000','YYYYMMDDHH24MISS') -- AND ELAPSED_TIME >= 1 * 1000000 * decode(executions,null,1,0,1,executions) and PARSING_SCHEMA_NAME = 'ZIPCODE' ORDER BY 평균실행시간 DESC, 실행횟수 DESC;
SELECT TO_CHAR (SID) sid, serial# serialNumber, SUBSTR (TO_CHAR (last_call_et), 1, 6) executeSeconds, userName, machine, b.sql_text sqlText FROM v$session a, v$sqltext b WHERE username NOT IN ('SYSTEM', 'SYS') AND a.TYPE != 'BACKGROUND' AND a.status = 'ACTIVE' AND a.sql_address = b.address(+) AND a.sql_hash_value = b.hash_value(+) ORDER BY a.last_call_et DESC, a.SID, a.serial#, b.address, b.hash_value, b.piece
현재 실행되고 있는 쿼리 와 실행 시간
SELECT TO_CHAR (SID) sid, serial# serialNumber, SUBSTR (TO_CHAR (last_call_et), 1, 6) executeSeconds, userName, machine, b.sql_text sqlText FROM v$session a, v$sqltext b WHERE username NOT IN ('SYSTEM', 'SYS') AND a.TYPE != 'BACKGROUND' AND a.status = 'ACTIVE' AND a.sql_address = b.address(+) AND a.sql_hash_value = b.hash_value(+) ORDER BY a.last_call_et DESC, a.SID, a.serial#, b.address, b.hash_value, b.piece
1. 스마트폰은 기본적으로 일정 시간동안 아무런 반응이 없으면 자동으로 화면이 꺼지게 됩니다.
원할 경우 실행되는 동안 화면을 안꺼지 게 할수 있습니다. getWindow().addFlags(WindowManager.LayoutParams.FLAG_KEEP_SCREEN_ON); 을 추가하게 되면 실행되는 동안 화면이 꺼지지 않습니다.
2. Dialog 타이틀바 없애기.
3. EditText에 이벤트 주기
EditText 이벤트는 addTextChangedListener() 를 사용하면 보다 쉽게 다룰수가 있었다.(setOnClickListener() 보다 좋음.)
et.addTextChangedListener(new TextWatcher(){
public void afterTextChanged(Editable arg0) {
// TODO Auto-generated method stub
}
public void beforeTextChanged(CharSequence s, int start, int count,
int after) {
// TODO Auto-generated method stub
}
public void onTextChanged(CharSequence s, int start, int before,
int count) {
// TODO Auto-generated method stub
}
});
Service는 background에서 처리를 계속할 수 있는 클래스이다. Service는 기본적으로 activity를 가지지 않는다.
서비스를 구현하기 위한 3가지 절차 -- Service 클래스를 확장한 새로운 클래스 정의 -- Manifest file에 Service 선언 추가 -- App에서 Service 실행
1. 서비스를 실행하는 클래스 - 타이머를 이용한 반복 처리.
public class MyService extends Service implements Runnable {
// 시작 ID
private int mStartId;
// 서비스에 대한 스레드에 연결된 Handler. 타이머 이용한 반복 처리시 사용.
private Handler mHandler;
// 서비스 동작여부 flag
private boolean mRunning;
// 타이머 설정 (2초)
private static final int TIMER_PERIOD = 2 * 1000;
private static final int COUNT = 10;
private int mCounter;
// 서비스를 생성할 때 호출
public void onCreate() {
Log.e("MyService", "Service Created.");
super.onCreate();
mHandler = new Handler();
mRunning = false;
}
// 서비스 시작할 때 호출. background에서의 처리가 시작됨.
// startId : 서비스 시작요구 id. stopSelf에서 종료할 때 사용.
//onStart는 여러번 호출될 수 있기 때문에 식별자로 사용.
public void onStart(Intent intent, int startId) {
Log.e("MyService", "Service startId = " + startId);
super.onStart(intent, startId);
mStartId = startId;
mCounter = COUNT;
// 동작중이 아니면 run 메소드를 일정 시간 후에 시작
if (!mRunning) {
// this : 서비스 처리의 본체인 run 메소드. Runnable 인터페이스를 구현 필요.
// postDelayed : 일정시간마다 메소드 호출
mHandler.postDelayed(this, TIMER_PERIOD);
mRunning = true;
}
}
// 서비스의 종료시 호출
public void onDestroy() {
// onDestroy가 호출되어 서비스가 종료되어도
// postDelayed는 바로 정지되지 않고 다음 번 run 메소드를 호출.
mRunning = false;
super.onDestroy();
}
// 서비스 처리
public void run() {
if (!mRunning) {
// 서비스 종료 요청이 들어온 경우 그냥 종료
Log.e("MyService", "run after destory");
return;
} else if (--mCounter <= 0) {
// 지정한 횟수 실행하면 스스로 종료
Log.e("MyService", "stop Service id = "+mStartId);
stopSelf(mStartId);
} else {
// 다음 작업을 다시 요구
Log.e("MyService", "mCounter : " + mCounter);
mHandler.postDelayed(this, TIMER_PERIOD);
}
}
// 원격 메소드 호출을 위해 사용
// 메서드 호출을 제공하지 않으면 null을 반환
public IBinder onBind(Intent intent) {
return null;
}
}
2. 서비스 실행, 종료를 사용자가 요청하는 클래스
// 서비스 시작과 종료를 요구하는 Activity
public class MyServiceActivity extends Activity {
ComponentName mService; // 시작 서비스의 이름
TextView mTextView; // 서비스 상태 표시
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
mTextView = (TextView)findViewById(R.id.text_view);
Button start = (Button)findViewById(R.id.start_button);
start.setOnClickListener(new View.OnClickListener(){
public void onClick(View v) {
startHelloService();
}});
Button stop = (Button)findViewById(R.id.stop_button);
stop.setOnClickListener(new View.OnClickListener(){
public void onClick(View v) {
stopHelloService();
}});
}
// 서비스 시작 요청
private void startHelloService() {
mService = startService(new Intent(this, MyService.class));
mTextView.append(mService.toShortString()+" started.\n");
}
// 실행한 서비스 중지 요청
private void stopHelloService() {
if (mService == null) {
mTextView.append("No requested service.\n");
return;
}
Intent i = new Intent();
i.setComponent(mService);
if (stopService(i))
mTextView.append(mService.toShortString()+" is stopped.\n");
else
mTextView.append(mService.toShortString()+" is alrady stopped.\n");
}
}
3. 사용자가 서비스 실행, 종료하는 화면 구성
<!-- 시작 --> <Button android:id="@+id/start_button" android:text="Start" android:layout_width="fill_parent" android:layout_height="wrap_content"/>
<!-- 종료 --> <Button android:id="@+id/stop_button" android:text="Stop" android:layout_width="fill_parent" android:layout_height="wrap_content"/>
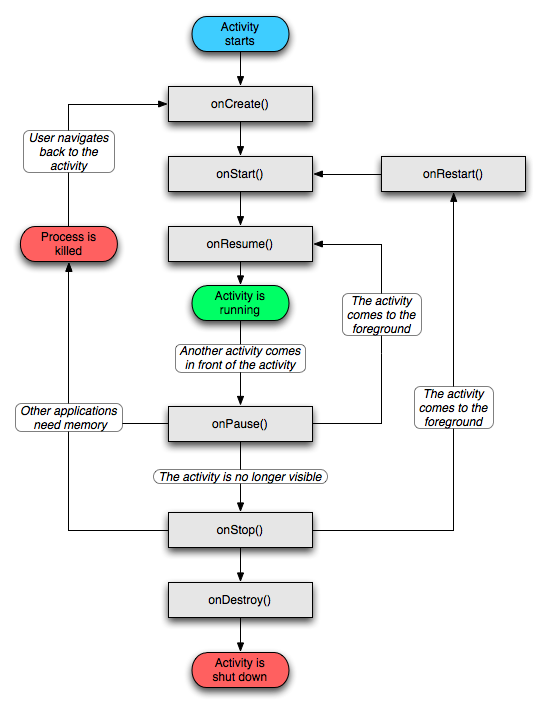
6. 컴포넌트의 생명주기 컴포넌트의 생명주기는 컴포넌트를 인스턴스화 할 때 시작해서, 인스턴스가 사라질 때 종료됩니다. 액티비티의 경우 그 사이에 활성화, 비활성화가 될 수 있기 때문에 사용자에게 보이거나 , 또는 보이지 않을 수도 있습니다.
1. 액티비티 생명주기
액티비티는 필수적으로 세 가지의 상태를 가지고 있습니다.
▣ 활성화(activity) 또는 실행 (running) 상태
액티비티가 포그라운드 화면으로 사용자에게 보이는 상태입니다 ( 즉, 현재 태스크에서 스택의 최상위에 위치하는 것). 이 상태는 사용자 액션을 받을 수 있게 됩니다.
▣ 멈춤(paused) 상태
사용자 액션을 받진 못하지만 여전히 보여지고 있는 상태입니다. 즉 다른 액티비티가 그 위에 위치하지만 해당 액티비티가 화면을 전부 채우지 않거나 투명해서 멈춤 상태의 액티비티를 볼 수 있는 상태입니다. 이 상태의 액티비티는 살아있습니다 ( 모든 상태정보와 멤버를 유지 중 ) 하지만 , 메모리 부족시엔 시스템에 의해 강제종료 될 수 있습니다.
▣ 정지 (stopped) 상태
완전히 다른 액티비티에 의해 가려진 상태입니다.더 이상 사용자에게 보이진 않지만 여전히 살아서(정보와 멤버유지) 있는 상태이죠. 여전히 보여지진 않기 때문에 메모리 부족시엔 강제종료 될 수 있습니다.
액티비티가 멈춤 또는 정지 상태라면, 시스템은 finish() 메소드를 호출하거나 프로세스를 강제종료 시킴으로서 메모리에서 제거할 수 있습니다. 종료된 액티비티가 다시 실행된다면, 다시 시작되어야 하고 이전 상태로 복구되어야 할 것입니다.
액티비티 상태변화
액티비티의 상태가 변하면 아래의 메소드가 호출됨으로써 변화가 통보되는데요. 이 메소들은 모두 프로텍티드(protected) 메소드입니다.
여기의 7가지 메소드들은 오버라이드 할 수 있습니다. 단,모든 액티비티는 최초 인스턴스 초기화를 위해 onCreate() 메소드는 무조건 구현해야 합니다.
또한, 액티비티 종료직전.... 마지막 기회가 될 수도 있는 시점에선 적절한 데이터 저장을 위해 onPause() 메소드도 구현해주면 좋겠네요.
액티비티 생명주기 메소드를 구현할 땐 항상 슈퍼클래스 버전을 호출하여야 합니다. protected void onPause() {
super.onPause() ;
}
네스티드 루프(nested loop)
액티비티 생명주기 메소드를 구현하여 볼 수 있는 것은 아래와 같습니다.
▣ 액티비티 인타이어 라이프타임 ( entire lifetime )
onCreate() 와 onDestroy() 메소드 사이에서 발생합니다. 액티비티는 onCreate() 메소드에서 모든 초기 설정을 하고 onDestroy()에서 모든 리소스를 해제하죠.
▣ 액티비티 비지블 라이프타임 ( visible lifetime )
onStart() 메소드에서 onStop() 메소드 사이에서 발생합니다. onStart() 메소드에서는 사용자 인터페이스의 변화 모니터를 위해 브로드캐스트 리시버를 등록할 수 있고 사용자가 보고있는 화면이 없을때엔 onStop() 메소드에서 제거할 수 있습니다. onStart() 와 onStop()은 액티비티가 사용자에게 보여지고 숨겨지는 상태이므로 여러번 호출 될 수 있습니다.
▣ 액티비티 포그라운드 라이프타임 ( foreground lifetime )
onResume() 메소드와 onPause() 메소드 사이에서 발생합니다. 이 기간동안 액티비티는 화면에서 다른 모든 액티비티보다 앞에 놓이며 사용자에게 보여집니다. onPause()는 기계가 꺼지거나 새로운 액티비티가 시작될 때 호출되고, onResume() 은 액티비티가 다시 복귀되거나 새로운 인텐트가 도착했을때 호출됩니다. 따라서 이 두개의 메소드 내용은 빠르고 가벼울 수록 좋겠네요.
생명주기 메소드가 하는 일
▣ onCreate()
액티비티가 최초 생성시에 호출됩니다. 초기화 설정을 하는 곳이지요. 보관된 상태의 액티비티가 있다면, 그 상태를 저장중인 Bundle 객체를 받습니다. onStart() 메소드가 이어집니다. 강제종료가 불가능 합니다.
▣ onRestart()
액티비티가 정지 후 다시 시작되기 바로 직전에 호출됩니다. onStart() 메소드가 이어집니다. 강제종료가 불가능 합니다.
▣ onStart()
액티비티가 사용자에게 보여지기 직전에 호출됩니다. 액티비티가 보여지게되면 onResume() 메소드가, 안보이게 되면 onStop() 메소드가 이어집니다. 강제종료가 불가능 합니다.
시스템이 다른 액티비티를 시작하려 할 때 호출됩니다. 일반적으로 데이터 저장을 하기에 좋은 곳입니다. 하지만 소스코드의 속도가 빨라야합니다. 왜냐하면이 메소드가 끝나기 전까진 다음 액티비티가 실행되지 않기 때문인데요, 액티비티가 되돌아오면 onResume(), 보이지않게되면 onStop() 이 이어집니다. 강제종료가 가능 합니다.
▣ onStop()
액티비티가 사용자에게 보이지 않을때 호출 됩니다. 액티비티가 제거되거나 다른 액티비티가 실행되어 해당 액티비티를 덮어버렸을 때, 호출되죠. 액티비티가 되돌아오면 onRestart(), 액티비티가 사라지면 onDestroy() 가 이어집니다. 강제종료가 가능 합니다.
▣ onDestroy()
액티비티 삭제 직전에 호출됩니다. 액티비티가 받는 마지막 호출 메소드가 되죠. 시스템이 메모리 확보를 위해 액티비티 인스턴스를 없애버려고 하거나 , finish() 메소드가 호출되면 호출되는 메소드입니다.
isFinishing() 메소드로 두 가지를 분기할 수 있습니다.
onStart() 메소드가 이어집니다. 강제종료가 불가능 합니다.
☞ 여기에서 onPause() 는 프로세스가 강제종료 되기 전에 호출되는 것입니다. 즉,프로세스가 강제종료 될 때 onPause() 는 무조건 호출되는 유일한 곳이 됩니다. (onStop(), onDestroy() 는 호출되지 않을 수 있어요), 따라서데이터 저장 등의 작업은 종료되기 직전에 호출되는 onPause() 에 구현해야 되겠네요.
액티비티 상태 저장하기
시스템이 액티비티를 강제종료 했을때, 사용자는 이전의 액티비티로 돌아가고 싶을 수 있습니다. 이럴 경우 액티비티가 강제종료 되기 전에 상태를 저장할 수 있는onSaveInstanceState()메소드를 구현하면 저장이 가능해 집니다.
즉, 액티비티가 파괴되기전에 호출되는 메소드 인데요. ( onPause() 호출 이전에 호출됩니다. ) 이 메소드는 이름/값 쌍으로 이루어진 번들 객체(Bundle) 를 인수로 가집니다. 액티비티가 다시 시작되면 번들은 onSaveInstanceState() 와 onStart() 이후에 호출되는onRestoreInstanceState()에게 전달됩니다.
☞ onSaveInstanceState() , onRestoreInstanceState() 메소드는 생명주기 메소드는 아닙니다. 따라서 항상 호출되지는 않으며 특정 상황 ( 액티비티 강제종료전에 onSaveInstance() 호출처럼 ) 에서만 호출됩니다. 단, 사용자 액션에 의해 종료될 때는 ( 사용자가 직접종료 ) 호출되지 않습니다. - 사용자가 되돌아가지 않을 생각으로 종료한 것으로 판단한 것이겠죠...
onSaveInstanceState() 는 액티비티의 일시적인 상태 저장을 위한 것이므로 , 데이터 등을 안전하게 저장하려면 onPause() 메소드에서 처리해야 합니다.
액티비티 생명주기 메소드의 순서
하나의 액티비티가 다른 액티비티를 시작할 때 하나는 멈추고 정지되며, 다른 하나는 시작되는 구조를 가집니다. 생명주기 메소드의 순서는 두 개의 액티비티가 동일 프로세스 안에 있을 때에 정의됩니다.
1. 현재 액티비티("A") 의 onPause() 가 호출됩니다. 2. 다음 시작되는 액티비티("B") 의 onCreate() -> onStart() -> onResume() 이 차례대로 호출됩니다 3. "B" 액티비티가 더 이상 사용되지 않으면 그것의 onStop() 이 호출됩니다.
3. 변수 역시 var를 사용하지 않으면 해당 변수는 전역변수로 인식한다. 그래서 대부분 사용자가 함수정의시에 var를 사용해서
다른 함수와 변수가 겹치지 않도록 지역변수로 선언한 것이다. 이것 역시 funtion example() { .........} 구분 밖에서 선언하면,
var를 사용해서 선언하였다 하더라도 { } 밖에서 선언한 것이라 전역변수가 된다.
이것은 추후에 함수 사용시 변수를 재사용할 수 있는 여부를 결정짓기 때문에 중요하다.
# 예제 소스
function checkUsername() {
request = createRequest();
if(request == null )
alert("unable to create request");
} else {
var theName = document.getElementById("username").value;
var username = escape(theName); <----- 특수문자들을 처리하기 위해서 escape 함수로 변수 처리
var url = "checkName.php?username=" + username;
request.onreadystatechange = userNameChecked; <-----결과가 나오면 처리할 함수를 설정
request.open("GET", url , true); <-----get, post방식, url, true(비동기), false(동기) 방식.
request.send(null);
}
# 예제 소스
- 보여지는 부분과 기능을 구현하는 것을 구분하는 방법은 CSS를 활용하여 보여지는 것을 구분하는 것이다. 즉 클래스를 설정한 후,
- 엘리먼트 찾기 : 엘리먼트들은 일종의 parent-child 관계이기 때문에 특정 element를 찾은 후, 다시 거기서 element검색이 가능하다.
function showTab() {
var selectedTab = this.title;
var images =
document.getElementById("tabs").getElementsByTagName("img"); <--- 특정 Element 안에 Element로 검색
for(var i =0 ; i < images.length; i++){
var currentImage = images[i];
}
}
예전에는 JavaScript에 대해 다양한 기술이 난무하여 표준이 없었으나, 산업이 발전하다 보니 표준기술보다는 산업의 기술(구굴, 페이스북 등)에서 프레임워크로 Ajax보다 뛰어난 것들이 많이 나오고 있다. 모든 것은 기본이 충실하면 이해가 쉬우니 느리더라도 단계를 밟아 가길 바라며, 바쁘다면 열심히 읽기 바란다.